Witam w kolejnej części bloga o LVS keepalived w której sprawdzimy czy to rzeczywiście działa i jakie ograniczenia posiada owa technologia.
Zasada działania.
Samą przeglądarką potwierdzimy stan działania, natomiast TCPDUMP na serwerze usługi powie czy prawidłowo przechodzi komunikacja.
tcpdump -i virbr1 -n 'port 80 and host 192.168.1.117' -q
14:09:34.108999 IP 192.168.1.117.47502 > 192.168.123.10.http: tcp 0
14:09:34.109209 IP 192.168.123.10.http > 192.168.1.117.47502: tcp 0
14:09:34.109241 IP 192.168.1.117.47502 > 192.168.123.10.http: tcp 0
14:09:34.109677 IP 192.168.1.117.47502 > 192.168.123.10.http: tcp 112
14:09:34.110086 IP 192.168.123.10.http > 192.168.1.117.47502: tcp 0
14:09:34.110114 IP 192.168.123.10.http > 192.168.1.117.47502: tcp 403
14:09:34.110129 IP 192.168.1.117.47502 > 192.168.123.10.http: tcp 0
14:09:34.112266 IP 192.168.1.117.47502 > 192.168.123.10.http: tcp 0
14:09:34.112495 IP 192.168.123.10.http > 192.168.1.117.47502: tcp 0
14:09:34.112524 IP 192.168.1.117.47502 > 192.168.123.10.http: tcp 0
Przypomnę, adres 192.168.123.10 jest adresem usługi, natomiast 192.168.1.117 jest adresem klienta. Nie ma tam innych adresów ? Właśnie w tym tkwi „magia” tego pomysłu. Komunikacja w kierunku usługi przechodzi przez LB, natomiast pakiety odpowiedzi do klienta są tworzone już na konkretnym serwerze który jak widać w odpowiedzi używa VIP jako adresu źródła.
Test I
Test na wyłączenie usługi httpd. JMeter posłuży mi jako symulator „natrętnego” klienta który bezustannie odpytuje usługę. Symulator klienta ma za zadanie ściągnąć 50k a potem 100k plik. By dodać realizmu, zadanie wykona zostanie w 10 wątkach tak jak robi to przeglądarka uzupełniając grafiką na wyświetlanej stronie
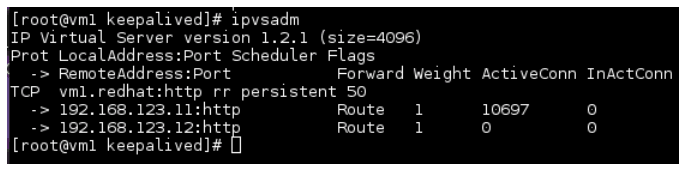
Jak widać na obrazku jeden z serwerów ma dość znaczne obłożenie. Jest to spowodowane przypisaniem adresu IP do konkretnego serwera oraz opcją „persistent 50” która zapamiętuje na 50 sekund przypisanie.
Wyłączam usługę po prostu zabijając serwer. Jako że JMetter nie daje się skonfigurować tak by błędy były dobrze wizualizowane w jednej tabelce, poniżej umieściłem dwie fotki wizualizujące całe zajście.

Powyższa tabelka zawiera statystyki dotyczące tylko i wyłączenie zapytań nie zrealizowanych.

Zapytania do usługi z prawidłowo zrealizowanymi zapytaniami.
Proszę się nie sugerować liczbami, test jest tak skonstruowany by maksymalnie szybko wysyłać zapytania. Test miał wykazać jak duży jest problem z HA i jak szybko keepalived wykryje zatrzymanie się serwera. Jak widać niedogodność istnieje przy 100% HA pierwsza tabelka powinna wskazywać 0 błędów. Jest to związane z tym że zapytania są przekazywane przez jakiś czas do niedziałającej usługi. Dla tych konkretnych ustawień środowiska przerwa w działaniu to około 3 sec. Keepalived ma ustawione sprowadzanie stanu co 6 sec (delay_loop 6), taki czasy w pesymistycznym wariancie by czekał klient na powrót usługi.
Test II
Jest jeszcze jeden element który może podlegać awarii, jest nim sam LB. Tutaj LVS + keepalived działa w konfiguracji active-pasive więc reszta LB, tylko oczekuje na awarię LB wybranego jako MASTER.
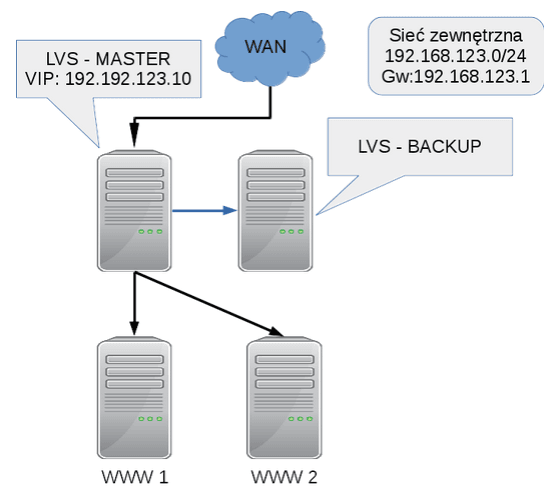
Powyższy schemat przedstawia budowę środowiska dla tego testu. Doszedł tylko jeden element, zapasowy load balancer .Test będzie przebiegał w dwóch etapach: wyłączenie wtyczki z LB – Mastera, oraz ponowne włączenie mastera i powrót do stanu pierwotnego infrastruktury. JMeter posłuży jako generator ruchu do serwerów. Jednocześnie będzie zbierał informację o powodzeniach dostępu do usługi.
Wyłączam MASTERa
Jan 29 04:16:35 vm2 Keepalived_vrrp[1649]: VRRP_Instance(VI_1) Transition to MASTER STATE
Jan 29 04:16:36 vm2 Keepalived_vrrp[1649]: VRRP_Instance(VI_1) Entering MASTER STATE
Jan 29 04:16:36 vm2 Keepalived_vrrp[1649]: VRRP_Instance(VI_1) setting protocol VIPs.
Jan 29 04:16:36 vm2 Keepalived_vrrp[1649]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.123.10
Jan 29 04:16:36 vm2 Keepalived_healthcheckers[1648]: Netlink reflector reports IP 192.168.123.10 added
Wycinek z loga zapasowego LB w którym widać jak Keepalived wykrył że MASTER nie działa i sam stał się masterem przypisując do siebie VIP oraz zaczął rozsyłać ARPy z nowym przypisaniem adresu IP do adresu MAC.
Włączam MASTER
Jan 29 05:13:13 vm2 Keepalived_vrrp[1649]: VRRP_Instance(VI_1) Received higher prio advert
Jan 29 05:13:13 vm2 Keepalived_vrrp[1649]: VRRP_Instance(VI_1) Entering BACKUP STATE
Jan 29 05:13:13 vm2 Keepalived_vrrp[1649]: VRRP_Instance(VI_1) removing protocol VIPs.
Jan 29 05:13:13 vm2 Keepalived_healthcheckers[1648]: Netlink reflector reports IP 192.168.123.10 removed
Jan 29 05:13:13 vm1 Keepalived_vrrp[2291]: VRRP_Instance(VI_1) Entering MASTER STATE
Jan 29 05:13:13 vm1 Keepalived_vrrp[2291]: VRRP_Instance(VI_1) setting protocol VIPs.
Jan 29 05:13:13 vm1 Keepalived_vrrp[2291]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.123.10
Jan 29 05:13:13 vm1 Keepalived_healthcheckers[2290]: Netlink reflector reports IP 192.168.123.10 added
Zamieściłem logi z obu instancji LB. Aktualny master staje się zapasowym, a z interfejsu usuwany jest VIP. Uruchomiony MASTER przypisuje do siebie adres VIP i w tym momencie przez niego przechodzi cała komunikacja.
Wynik
 LB master wynik
LB master wynikZerowa utrata pakietów! Ani jedno połączenie nie zostało utracone nawet dla tak intensywnego ruchu jak w tym teście tj. 1699 zapytań na sekundę. To właśnie jest wysoka dostępność
Podsumowanie
LVS + keepalived nie jest prosty w konfiguracji, należy posiadać wiedzę z paru dziedzin: sieci, administrowania linuxem oraz konfiguracji samych usług. Mimo tego jest wstanie zapewnić te same opcje rozkładania ruchu jak odpowiedniki sprzętowe.
Oczywiście są pewne niedociągnięcia w HA, co wykazał pierwszy test, jeśli jednak sekundowe przerwy w działaniu usług są dopuszczalne a priorytetem jest obsługa dużych wolumenów zapytań , to rozwiązanie jest warte sprawdzenia na Twojej infrastrukturze.